
 •
• About this article
This article explains how the “reactive-programming” approach helps us to create an awesome infinite-scroll-list in only a few lines of code. For this article, we are going to use RxJS and Angular. If RxJS is completely new, it might be a good idea to read the documentation first. Whether we use Angular or something else like React, it shouldn’t really interfere with the clarity of this article.
Reactive programming
Reactive programming is a rather old but very powerful approach of solving problems. However, we can run into problems when trying to think in a completely reactive manner. Thinking reactively is a huge mind switch that we must make to completely accept this “new” way of coding things. The whole “Our application reacts to a state-management-layer like redux” principle is grasped quite quickly (it’s reactive programming too), but when it comes to thinking in streams it can become quite difficult in the beginning.
Why reactive programming?
Reactive programming has some advantages over imperative programming.
- No more “if this, then that” scenario’s
- We can forget about a ton of edge-cases<
- It’s easy to separate presentation logic from other logic (The presentation layer will just react to streams)
- It’s a standard: widely supported by tons of languages
- When we grasp the concepts, we write complex logic in a few lines of code in a very simple manner
A few days back a colleague of mine came to me with this problem: He wanted to create an infinite-scroll in Angular but he had bumped into the boundaries of imperative programming. It turned out that an infinite-scroll-solution was actually a great use-case to explain how reactive programming can help you write better code.
The infinite scroll
What should it do?
An infinite-scroll-list, is a list where the data is being loaded asynchronosly when the user scrolls further down the application. It’s a great way to avoid a pager (where the user had to click on every time) and it can really keep the application performant. It’s an efficient way to keep bandwidth low and increase the user-experience.
For this scenario, let’s say that every page contains 10 results and that all the pages with results are being shown as one long scrollable list => the infinite-scroll-list.
Let’s list the features of what our infinite-scroll-list must do:
- It should load the first page by default
- When the results of the first page don’t fill the page completely, it should fill page 2, and so on, until the page is full
- When the user scrolls down, it should load page 3, and so on…
- When the user resizes it’s window, and more space is being freed for results, it should load the next page
- It should make sure that it doesn’t load the same pages more than once (caching)
Let’s draw it first
Like most coding decisions, drawing them on a whiteboard first might be a good idea. That might be a personal approach, but it helps us not to write code that will be removed/refactored later.
Based on the feature-list, there are three actions that will trigger the application to load data: Scrolling, resizing, and a manual action that will be triggered to manually fetch pages. When thinking reactively we can see 3 sources of events happening, let’s call them streams:
- A stream of scroll events: scroll$
- A stream of resize events: resize$
- A manual stream where we can manually decide what page to load: pageByManual$
Note: We will suffix the streams with $ to indicate that they are streams, this is a convention (personal preference)
Let’s draw these streams on a whiteboard:

These streams would contain certain values over time:
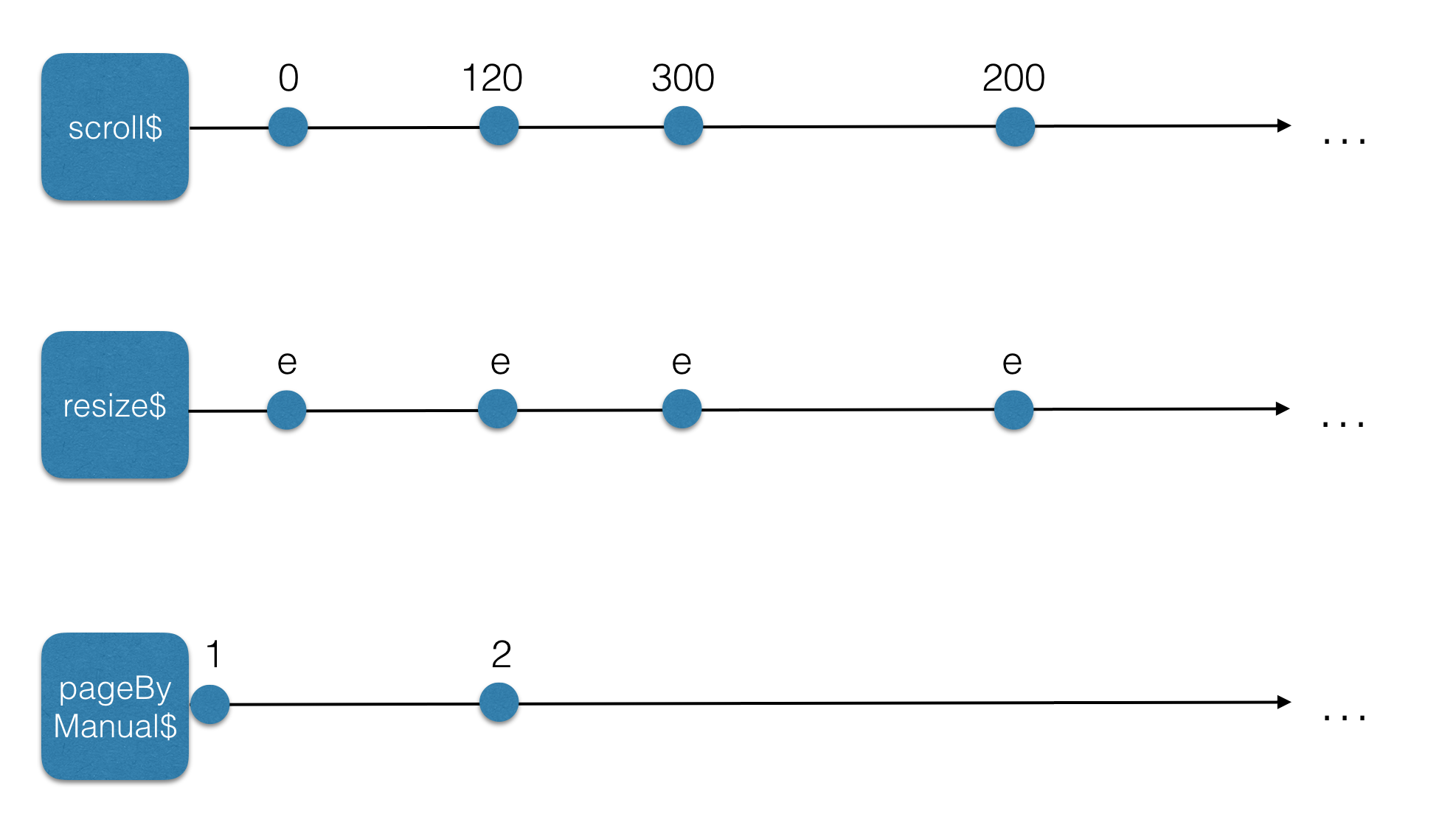
The scroll$ stream has Y values, which we can use to calculate the page number.
The resize$ stream has event values. We don’t need the values but we do need to know when the user resizes its window.
The pageByManual$ will contain page numbers, which we can set directly since this is a subject (more on that later).
What if we could map all these streams, to streams that would contain page numbers? That would be awesome, because based on the page number, we could load a specific page. How we map the current streams to page number-streams is not something that we need to think about right now (we are just drawing remember?). The next drawing might look something like this:
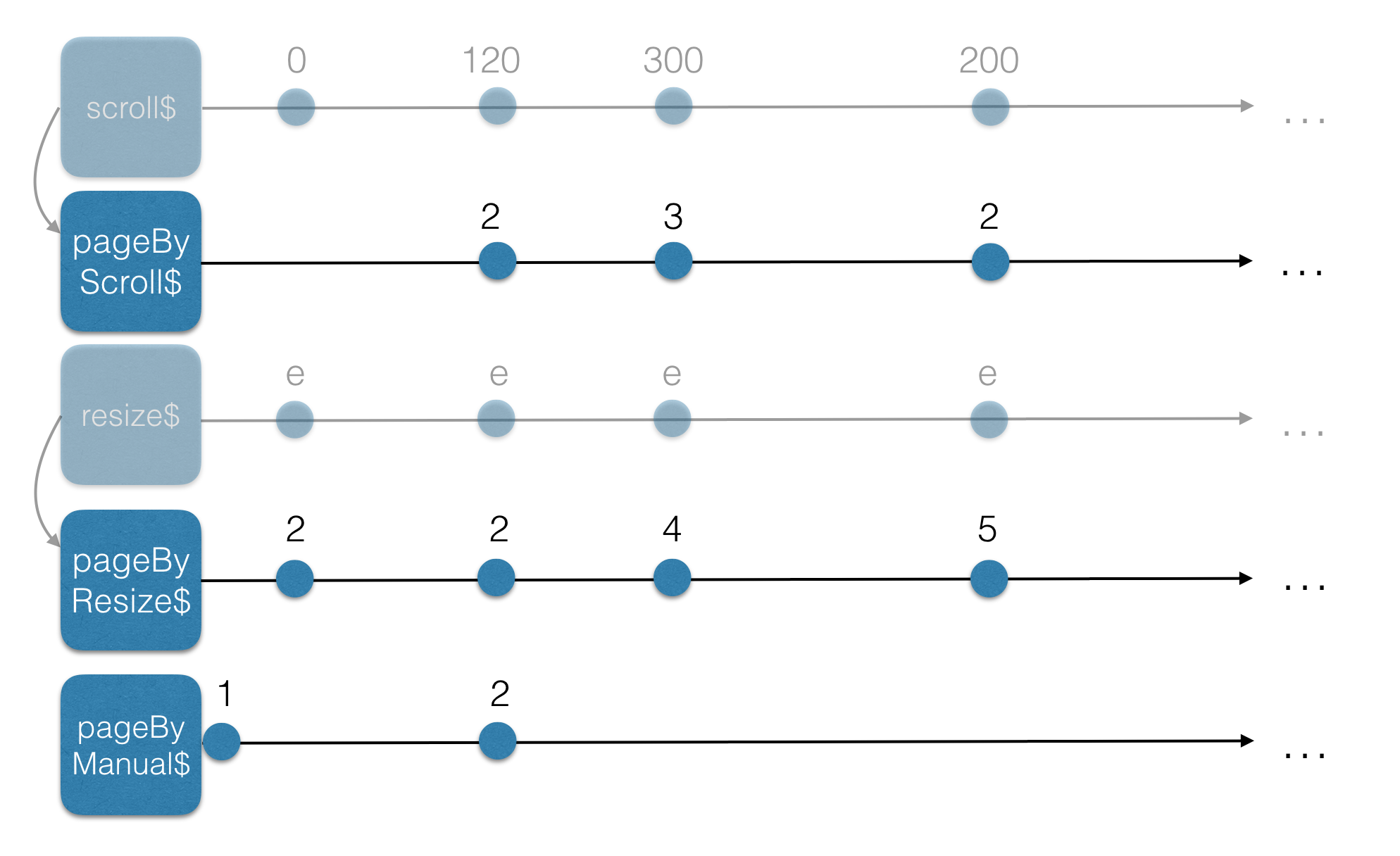
We can see that we have created the following streams based on our initial streams:
- pageByScroll$: which contains page numbers based on the scroll-events
- pageByResize$: which contains page numbers based on the resize-events
- pageByManual$: which contains page numbers based on manual events (for instance, if there is still whitespace on the screen, we have to load the next page)
What if we could merge these 3 page-number streams in an efficient manner, than we would get a new stream called pageToLoad$, that would contain page numbers created by scrolling-events, resize-events, and manual events.
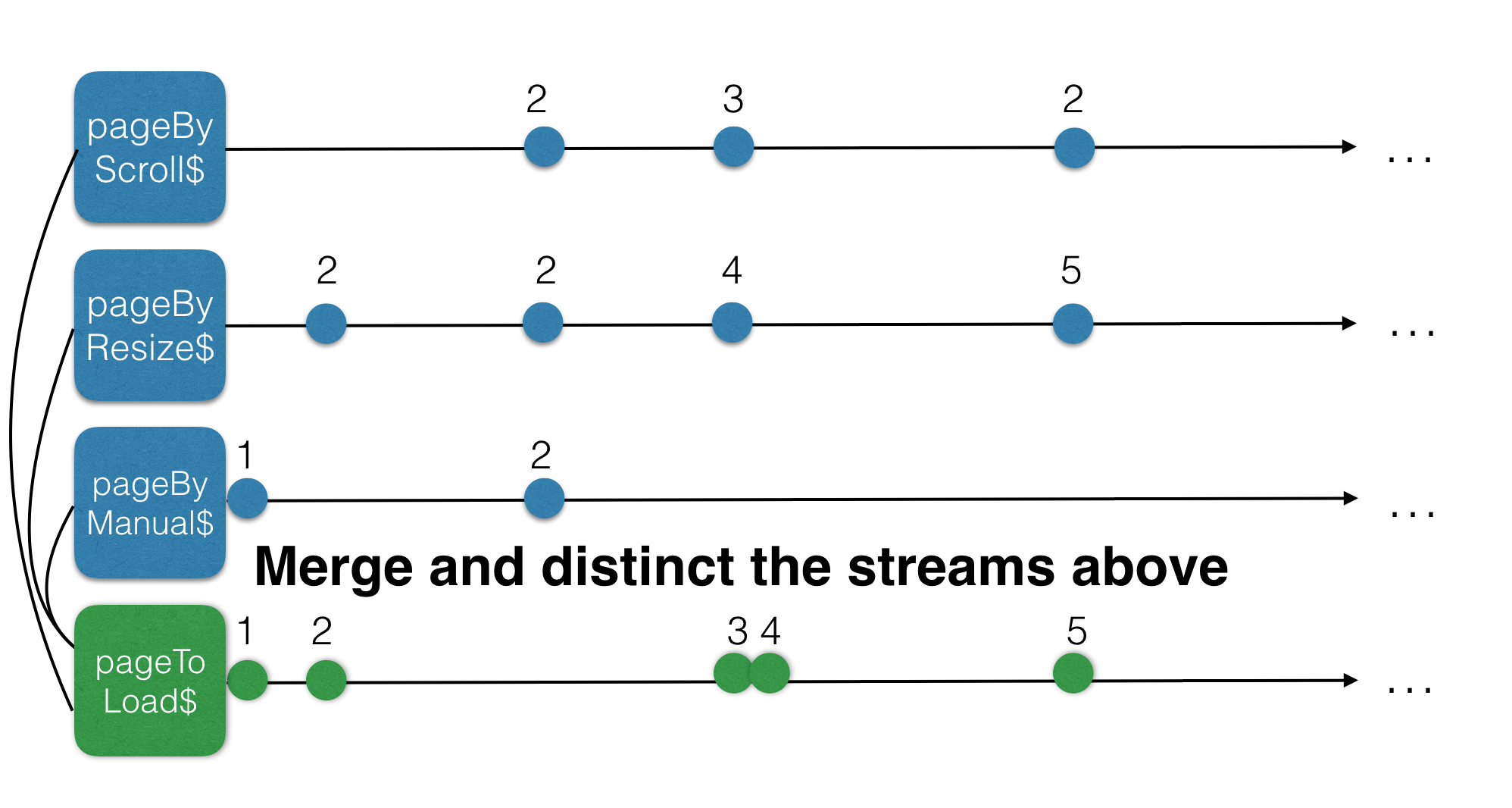
If we subscribe to the pageToLoad$ stream and than fetch data from the service, part of our infinite scroll would work. However, we were thinking reactively right? That also means, avoid subscriptions as much as possible… We actually need a new stream based on the pageToLoad$ stream that contains the results of our infinite scroll list…
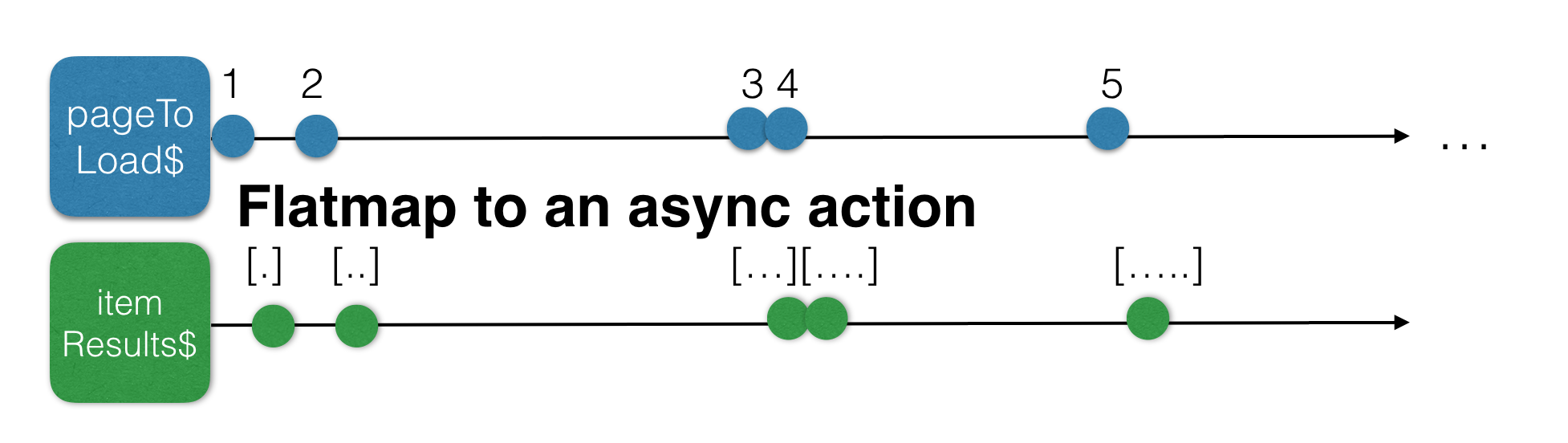
Now let’s throw this in one big schema.
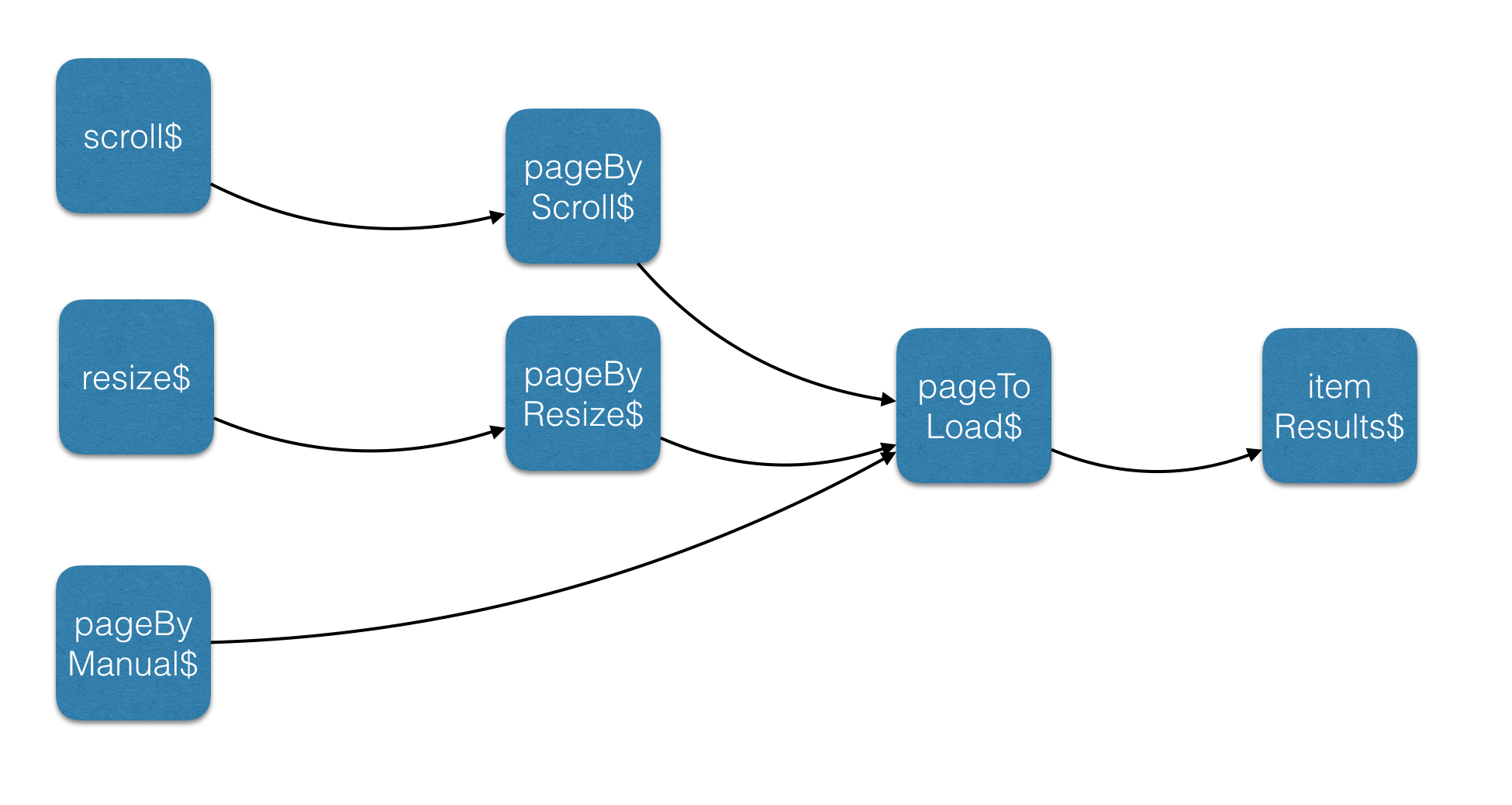
As we can see above we have 3 input streams: one for scrolling, one for resizing and a manual one. Afterwards we have 3 page streams that are based on the input streams. When merging these streams we can create a pageToLoad$ stream. Based on that pageToLoad$ stream, we will fetch the data.
Let’s code
We have drawn more than enough, we have a clear vision of what our inifinte-scroll-list should do, so let’s start shall we?
To calculate which page needs to be loaded we need 2 properties:
private itemHeight = 40;
private numberOfItems = 10;// number of items in a page
pageByScroll$
The pageByScroll$ stream might look something like this:
private pageByScroll$ =
// first of all, we want to create a stream that contains
// all the scroll events that are happening in the window object
Observable.fromEvent(window, "scroll")
// we are only interested in the scrollY value of these events
// let's create a stream with only these values
.map(() => window.scrollY)
// create a stream with the filtered values
// we only need the values from when we are scrolling outside
// our viewport
.filter(current => current >= document.body.clientHeight - window.innerHeight)
// Only when the user stops scrolling for 200 ms, we can continue
// so let's debounce this stream for 200 ms
.debounceTime(200)
// filter out double values
.distinct()
// calculate the page number
.map(y => Math.ceil((y + window.innerHeight)/ (this.itemHeight * this.numberOfItems)));
// --------1---2----3------2...
note: In real applications you might want to use injected services for window and document
pageByResize$
The pageByResize$ looks like this:
private pageByResize$ =
// Now, we want to create a new stream that contains
// all the resize events that are happening in the window object
Observable.fromEvent(window, "resize")
// when the user stops resizing for 200 ms, then we can continue
.debounceTime(200)
// calculate the page number based on the window
.map(_ => Math.ceil(
(window.innerHeight + document.body.scrollTop) /
(this.itemHeight * this.numberOfItems)
));
// --------1---2----3------2...
pageByManual$
The pageByManual$ is the stream we use to have an initial value (initial page to load), but it’s also something that we need to control manually. A Behavior subject looks perfect for the job, because we need a stream that has an initial value where we can also manually add values. A behavior subject is just a stream that has an initial value and can be manipulated over time.
private pageByManual$ = new BehaviorSubject(1);
// 1---2----3------...
pageToLoad$
Awesome, we have the 3 streams with page inputs, now let’s create a pageToLoad$ stream.
private pageToLoad$ =
// merge all the page streams and create a new stream of those
Observable.merge(this.pageByManual$, this.pageByScroll$, this.pageByResize$)
// create a new stream where the double values are filtered out
.distinct()
// check if the page is already in the cache (just an array property in our component)
.filter(page => this.cache[page-1] === undefined);
itemResults$
The hard part is over. We now have a stream with the page we have to load in there, which is super useful. We don’t need to care anymore about corner cases or other complex logic. Every time a new value in that stream is added, we just need to load the data. That’s it!!
We will use flatmap for this because the fetch-data-call will return a stream as well. FlatMap (or MergeMap) will merge these 2 streams as one.
itemResults$ = this.pageToLoad$
// based on that stream, load our asynchronosly data
// flatmap is an alias for mergemap
.flatMap((page: number) => {
// load me some starwars characters
return this.http.get(`https://swapi.co/api/people?page=${page}`)
// create a stream that contains the results
.map(resp => resp.json().results)
.do(resp => {
// add the page to the cache
this.cache[page -1] = resp;
// if the page contains enough white space, load some more data :)
if((this.itemHeight * this.numberOfItems * page) < window.innerHeight){
this.pageByManual$.next(page + 1);
}
})
})
// eventually, just return a stream that contains the cache
.map(_ => flatMap(this.cache));
The result
the complete result might look like this: Note the async pipe that puts the whole subscription process into play
@Component({
selector: 'infinite-scroll-list',
template: `
<table>
<tbody>
<tr *ngFor="let item of itemResults$|async" [style.height]="itemHeight + 'px'">
<td></td>
</tr>
</tbody>
</table>
`
})
export class InfiniteScrollListComponent {
private cache = [];
private pageByManual$ = new BehaviorSubject(1);
private itemHeight = 40;
private numberOfItems = 10;
private pageByScroll$ = Observable.fromEvent(window, "scroll")
.map(() => window.scrollY)
.filter(current => current >= document.body.clientHeight - window.innerHeight)
.debounceTime(200)
.distinct()
.map(y => Math.ceil((y + window.innerHeight)/ (this.itemHeight * this.numberOfItems)));
private pageByResize$ =
Observable.fromEvent(window, "resize")
.debounceTime(200)
.map(_ => Math.ceil(
(window.innerHeight + document.body.scrollTop) /
(this.itemHeight * this.numberOfItems)
));
private pageToLoad$ = Observable
.merge(this.pageByManual$, this.pageByScroll$, this.pageByResize$)
.distinct()
.filter(page => this.cache[page-1] === undefined);
itemResults$ = this.pageToLoad$
.do(_ => this.loading = true)
.flatMap((page: number) => {
return this.http.get(`https://swapi.co/api/people?page=${page}`)
.map(resp => resp.json().results)
.do(resp => {
this.cache[page -1] = resp;
if((this.itemHeight * this.numberOfItems * page) < window.innerHeight){
this.pageByManual$.next(page + 1);
}
})
})
.map(_ => flatMap(this.cache));
constructor(private http: Http){
}
}
Here is a working plunk
Again, (like I try to prove in previous articles) We don’t need to use third party solutions for everything. The infinite-scroll-list doesn’t contain that much code, and it’s very flexible. Let’s say that we would like to free up DOM-elements and use only 100 items at a time, we could just create a new stream for that :)
Thanks for reading, I hope you enjoyed it.
